In the last post of this series on
nullitis we look at how pervasive and distracting null-checking is.
This new post focus on the object-oriented way of mitigating this problem.
But first, we should remember what is all the object orientation about. In simple terms, OO programs are just a network of state-encapsulating entities called objects sending messages around to perform computation.
We can visualize this with a sample financing application in which you have an
object p1 representing an investment portfolio, when the line
p1.estimateValue(currentIndexes) gets executed, a message tagged
estimateValue with payload currentIndexes is sent to the p1 object. As
a response, p1 can change its state, send more messages to the constituent
investments and/or return computed values.
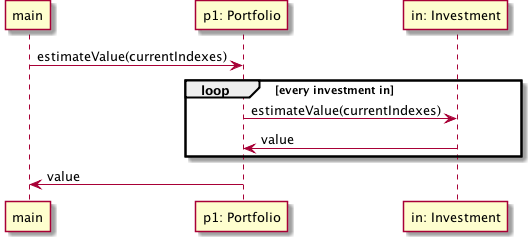
This simple scheme scale by allowing you to break the problem into objects that solve part of the problem and send messages (method invocations) to allow their fellows to solve the rest. A crucial point here is that messages decouple sender from receiver. In statically typed languages that means that any object implementing an interface1 can play the role of receiver and multiple implementations of the method could be called for different objects. For that reason, this is known as subtype polymorphism.
Contrary to the popular belief, OO is less about inheritance, factories and
the singleton pattern than about polymorphism. Going back to the investment
example, the p1 portfolio object is concerned just with adding up the
estimates for every individual investment. Every investment object must
accept the estimateValue message (i.e. implement the Investment
interface) but can do it in a completely different way. For instance, some
investments could be private bonds paying a periodic interest while others
can be treasury bills following a completely different path.
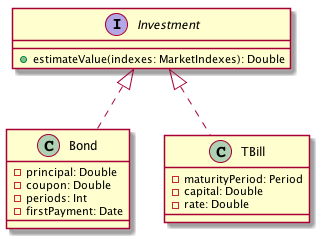
This has very far reaching ramifications that go from modest achievements, like enabling you to add more and more investment types without changing the portfolio code, to more important ones like allowing for dependency inversion, a general principle that states that details should depend on abstractions2.
With this simplified view of OO (Alan Kay, forgive me!) we can look again to
the null-checking code. When a reference is nullable we need to guard its
use with a check because null does not accept any message3. Why not
represent missing values with objects able to accept those messages? Enter
the null object pattern.
We can apply this idea by writing an implementation of Investment for the
case of not investing at all. This no-investment, or NullInvestment, holds
just the amount of available capital.
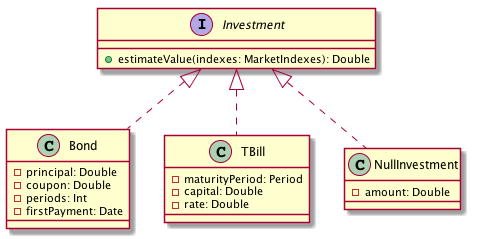
A NullInvestment instance could be returned as the best investment when
nothing else is possible instead of null. Or it could be used as well as
the initial value before the user selects an actual investment strategy
instead of having a null. And so on!
If we think about it, the value of this pattern lies on removing all
null-checks scattered all over the place to a new special-case
class4. The rest of the code become simpler as it just contains the
polymorphic call with no exceptions. This works very well for recursive
structures (null/leaf nodes), objects aggregating components that might be
missing, searches, process that could fail, event handlers, etc.
Another example could happen when some API provide a progress callback,
typically providing an interface like ProgressListener. This makes very
easy to plug an implementation that reports progress to the standard output.
interface ProgressListener {
void onProgress(double progress);
}
class PrintProgress implements ProgressListener {
@Override
public void onProgress(double progress) {
System.out.format("Progress: %5.2f\n", progress * 100);
}
}If we want that a relatively complex process called FooProcess report
progress when a listener is provided we can create a couple of constructors
(with/without listener) and check for null whenever there is progress.
class FooProcessor {
private final ProgressListener listener;
public FooProcessor() {
this(null); // Don't do this at home
}
public FooProcessor(ProgressListener listener) {
this.listener = listener;
if (this.listener != null) {
this.listener.onProgress(0);
}
}
public void run() {
...
if (this.listener != null) {
this.listener.onProgress(++n / total);
}
...
if (this.listener != null) {
this.listener.onProgress(1);
}
}
}Alternatively, we can apply the null object pattern and write a
NullProgressListener.
class NullProgressListener implements ProgressListener {
@Override
public void onProgress(double progress) {
// Do nothing
}
}This will make null-check free the implementation of the process:
class FooProcessor {
private final ProgressListener listener;
public FooProcessor() {
this(new NullProgressListener);
}
public FooProcessor(ProgressListener listener) {
this.listener = listener;
this.listener.onProgress(0);
}
public void run() {
...
this.listener.onProgress(++n / total);
...
this.listener.onProgress(1);
}
}As you can see, this is a valuable pattern but it is far from being a silver bullet as there are several limitations to its applicability.
First of all, the null object must respond to the same messages than the regular ones and nothing guarantees that a reasonable implementation could be possible. A null event handler can do nothing, the null investment just provide no gains at no risk but what is the marriage state of a null employee? Apart from that, the implemented behavior can be coupled with the client code leading to non-obvious return values.
Other important limitation lies on the very fact of the null object behaving like the real thing. That could mask errors making very difficult to track them to their root cause.
Finally, the pattern will work better on behavior-encapsulating objects but not as well on value objects in which polymorphism and data encapsulation are on a second plane.
-
Alternatively any subclass of a base class, typically declared abstract. ↩
-
You can apply this principle by defining an abstract interfaces and make all client code to depend on them and, at runtime, concrete implementations of the interfaces must be provided. If you think about that, this is exactly what makes frameworks possible at all. ↩
-
The substitution principle of Liskov is the rule of thumb for when a class is a subtype of other and can be resumed as being able to act as a member of the base class. The
nullvalue violates this principle when used as a value of other classes as just raises exceptions on any method call. ↩ -
The null object pattern is in fact a particular case of the special case object pattern you can find on the Refactoring book of Martin Fowler (a good reading IMHO). ↩